Do You Have Questions?
WhatMaster.com is here to answers!
We want to personally welcome you to our site! We are excited that you have found us, and we look forward to educating you on a tons of different answers of your questions that will teach you all the aspects, as well as other informative and interesting articles on topics. There is always something new and exciting to be seen in WhatMaster.com, and we can’t wait to show you all WhatMaster.com have to offer.
Explore Answers Of Your Questions Alphabetically
Recent Work
-
Marie Dee Coo Model Age Biography
Hello, Guys Welcome to our Website. Today we will give you information about a Famous Female Fitness Mode, who is…
Read More » -
Chemistry
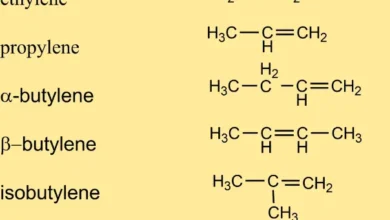
Examples Of Alkenes And Characteristics In Chemistry
Alkenes are chemical elements with double bonds or carbon double bonds. Its general formula is CnH2n. Alkene Definition Alkenes are…
Read More » -
20 Examples Of Logical Semantics
Logical semantics is a branch of logic that focuses on studying the meaning of statements and arguments through formal structures.…
Read More » -
Game Boy Advance Apk
The Game Boy Advance (GBA) was a popular handheld gaming system developed using the Game Boy game simulator. Released in…
Read More » -
Soft Puzzle Drop The Slime Apk
Soft Puzzle – Drop The Slime APK – Simple and Easy! But that’s why this is the funnest puzzle game…
Read More »